论文分享
0. 前言
Pavel Ostyakov, Roman Suvorov, Elizaveta Logacheva1 Oleg Khomenko, Sergey I. Nikolenko
一作Pavel Ostyakov是莫斯科三星AI中心的人员,在 Kaggle Cdiscount’s Image Classification Challenge 比赛中获得第一名,YouTube 视频,github:https://github.com/PavelOstyakov?tab=repositories,他参加的 Kaggle 比赛多一点。
论文代码还没有公布。
1. Introduction

要解决的问题是图像合成,一共三件事:剪切、贴图、修复。即如何把一张图片的物体剪切下来,然后贴到另一张背景图上,并且补全被剪掉的区域。
并且实验证明,结果不仅合成的新图片逼真,而且分割也做得很好。
This process consists of three basic operations: (1) cut, extracting an object from image; (2) paste and enhance, making the pasted object appear natural in the new context; (3) inpaint, restoring the background after cutting out an object
关键词:语义分割、贴图、去目标、补全、修复、GAN、image generation、图像合成
备注:训练过程不需要成对图片。
相似工作:Learning to segment via cut-and-paste
通过作者的论述,思想相同的地方很多。
2. Methods
2.1 Problem Setting and General Pipeline
字符表示:
| 字符 | 含义 |
|---|---|
| $x= |
图片$x$,由目标$O$和背景$B_x$组成 |
| $y=<\emptyset,B_y>$ | 图片$y$,包含背景$B_y$,没有目标 |
| $Y=\{<\emptyset,By>\}{y\in Y}$ | 背景数据集 |
| $X=\{ |
不同物体在不同背景的图片 |
| $m$ | 目标$O$在图片$x$上的mask $m$ |
| $\hat{x}=<\emptyset,\hat{B}_x>$ | 去除目标只剩背景$B_x$并修复后的图片 |
| $\hat{y}=<\hat{O},\hat{B}_y>$ | 将目标粘贴到背景$B_y$并增强后的图片 |
问题定义:
对于任意一组图片$x=
步骤分解:
- 分割(segmentation):预测图片$x=
$\odot$ denotes componentwise multiplication;
增强(enhancement):对于$z$,做进一步图片增强,使其更自然,得到$\hat{y}=<\hat{O},\hat{B}_y>$
修复(inpainting):对于去除目标后的图片$(1-m)\odot x$,修复成$\hat{x}=<\emptyset,\hat{B}_x>$
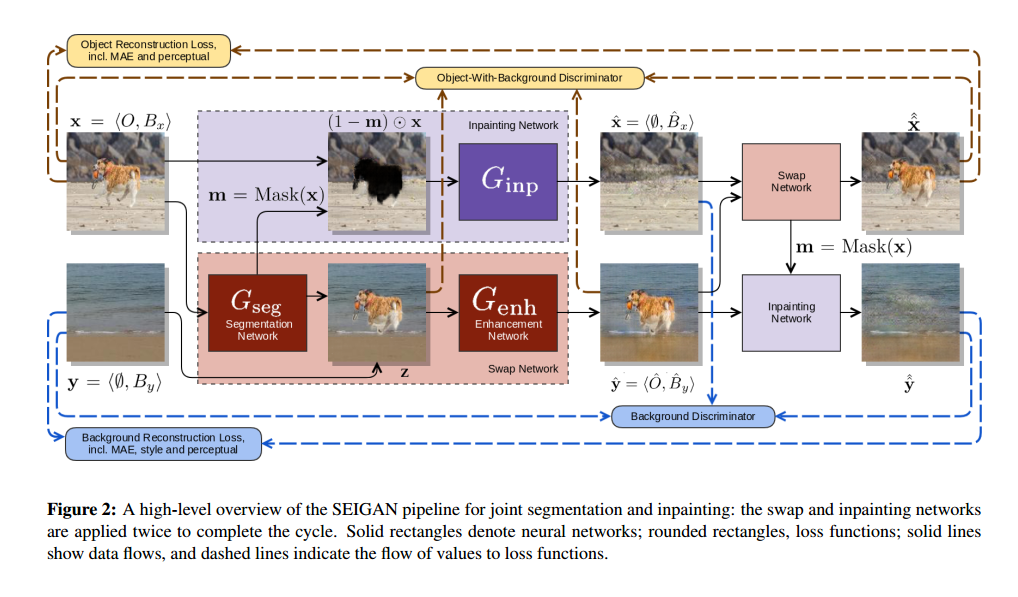
其中 swap network 就是 segmentation network 和 enhancement network 的组合。
- 类似CycleGAN,网络架构应用两次,第一次得到$\hat{x}$和$\hat{y}$,第二次得到$\hat{\hat{x}}$和$\hat{\hat{y}}$
- $G_{seg}$:Fig.3.right,输入$x=
- $G_{inp}$:Fig.3.left,输入$(1-m)\odot x$,输出$\hat{x}=<\emptyset,\hat{B}_x>$
- $G_{enh}$:Fig.3.left,输入$z=m\odot x+(1-m)\odot y$和噪声,输出$\hat{y}=<\hat{O},\hat{B}_y>$
- $D_{bg}$:背景判别器,判断真背景($y$)和假背景($\hat{x}$、$\hat{\hat{y}}$),真为1,假为0
- $D_{obj}$:目标判别器,判断背景和目标是一体的($x$)和背景和目标是合成的($z$,$\hat{y}$),一体的为1,合成的为0.
2.2 The inpainting Network $G_{inp}$
背景对抗损失函数:
背景重构损失函数:
其中,$VGG_1(y)$表示VGG19的前五层,$VGG_2(y)$表示VGG19的后五层
$G_{inp}$ 的网络架构:
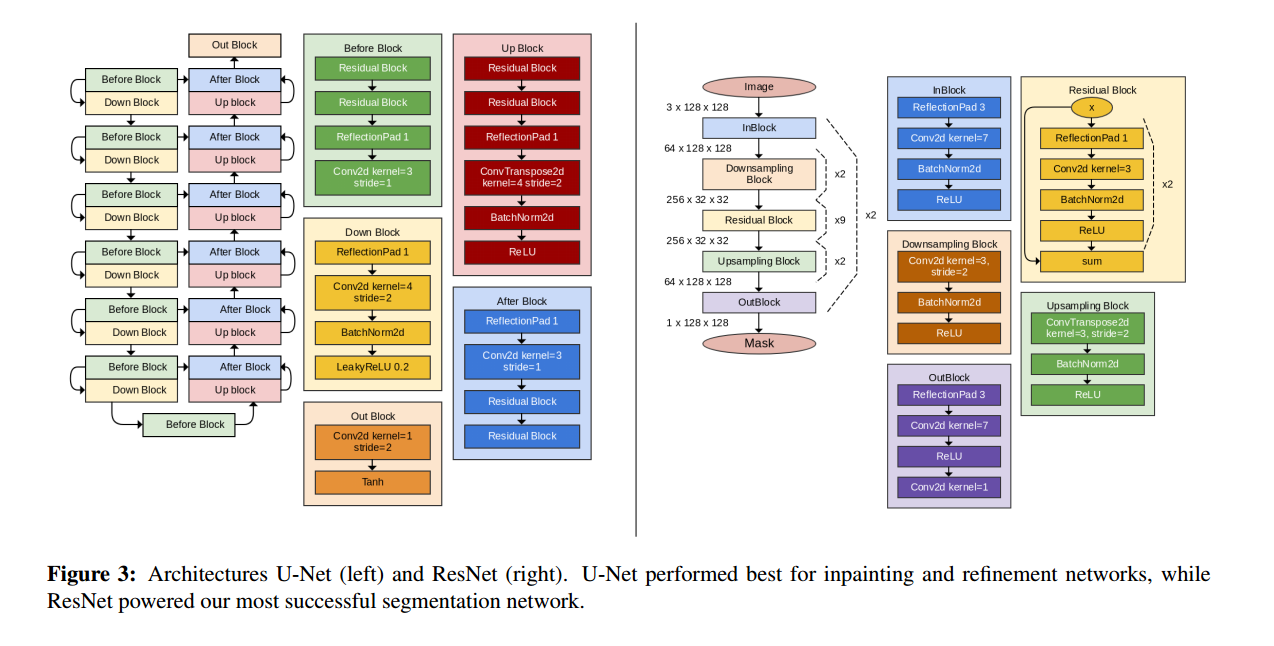
其实没太看懂这个网络,可能还是需要有代码。
2.3 The Swap Network
The swap network = the segmentation network + the enhancement network
目标重构损失函数:
目标对抗损失函数:
identity loss:
2.4 Total Loss Funcion, Remarks, and Network Architectures
The Generator Loss:
The Discriminator Loss:
Remarks:
- a pool of fake images,类似Cycle GAN也有。
- 对于不同大小和比例的图片$x,y$,作者使用了增强网络
- texture loss $l^{rec}_{bg}$ 比 threshold 作用在 mask m 上的效果更好
In our setup this problem is addressed by a separate enhancement network, so we have fewer limitations when looking for appropriate training data.
3. Experimental evaluation
实验性能主要分为两个:
- 生成图片的主观真实性
- 生成分割掩码的准确性
生成图片的主观真实性: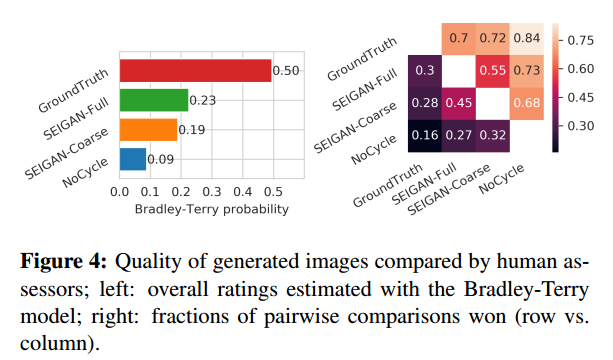
从Fig.4.left可以简单地看出,Full的效果还是很明显的。
生成分割掩码的准确性: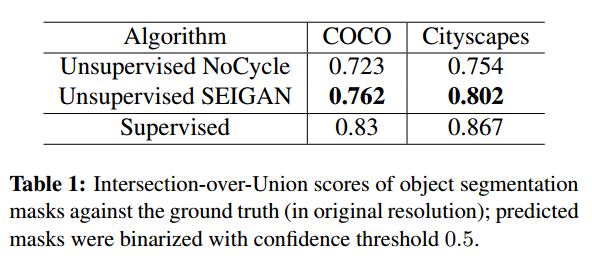
实验效果:
4. Future
这个方法是否可以用在两个图片的目标对换呢?如果用在跨数据集的行人重识别上,那么是否可以将源数据集的行人粘贴在目标数据集上呢?好像有一个GAN就是类似的.
Person Transfer GAN to Bridge Domain Gap for Person Re-Identification