0. 前言 这篇文章是根据GANnotation的一个公式查过来的,感觉还挺厉害。
关键词:starGAN的改进、连续的表情变换、贴回去能够一致
1. Introduction 在人脸转换中,StarGAN是最成功的GAN,但是只能生成离散的人脸。作者要做的就是生成连续的表情变化。
符号
含义
$\mathrm{I}_{y_r}\in \mathbb{R}^{H×W×3}$
输入图片
$\mathrm{y}_r=(y_1,…,y_N)^T$
其中,每一个$y_i$表示第i个action unit的程度,在0~1之间
$\mathrm{I}_{y_g}$
输出图片
$\mathcal{M}$
映射函数M: $(\mathrm{I}{y_r},\mathrm{y}_g)$—>$\mathrm{I} {y_g}$
非成对图片
3. Our Approach
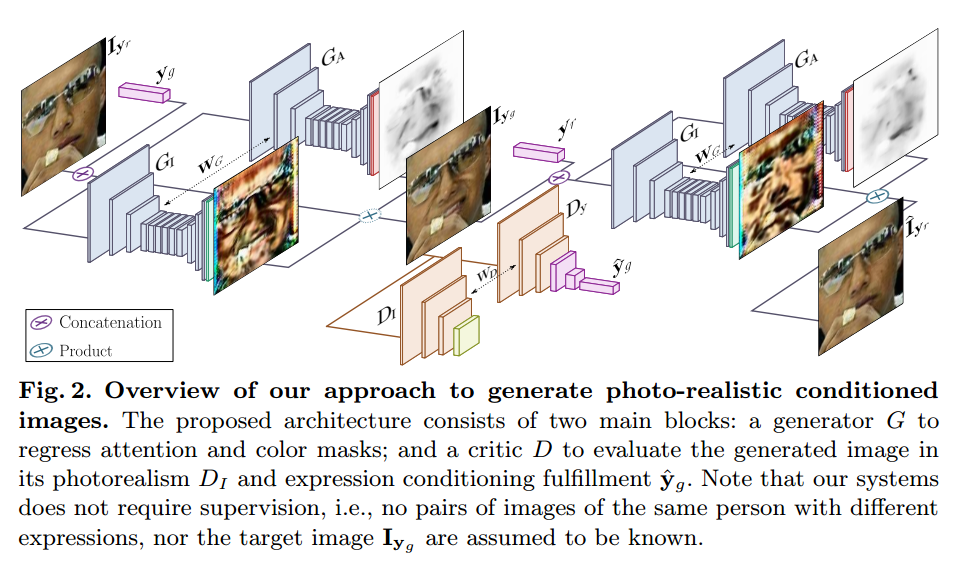
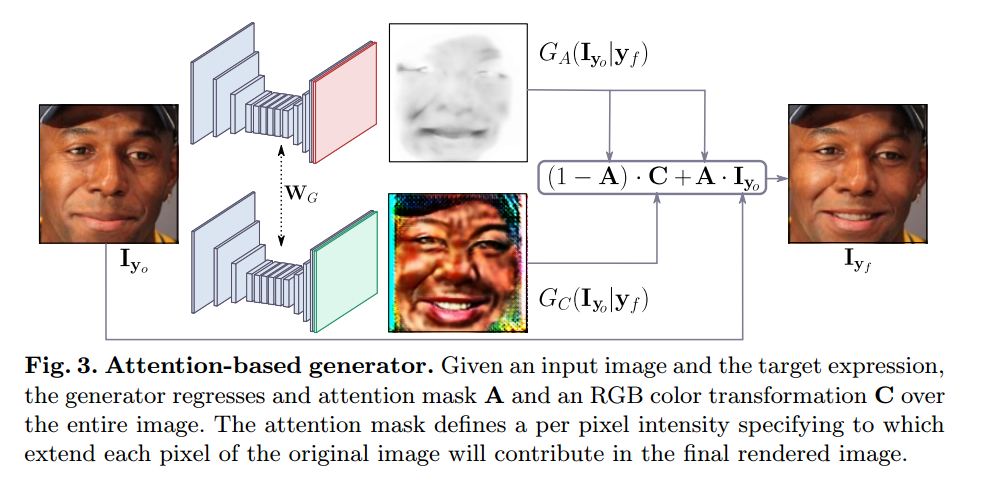
3.1 Network Architechture 3.1.1 Generator 对于G的改进,为了能够使G只聚焦于对于新表情的生成,而保留其他元素,引入attention机制,也就是G生成的不是一整张图片,而是两个mask,color mask C 和 attention mask A.即:
其中,$\mathrm{A}=GA(\mathrm{I} {\mathrm{y}o}|\mathrm{y}_f)\in \{0,…,1\}^{H×W}$,$\mathrm{C}=G_C(\mathrm{I} {\mathrm{y}_o}|\mathrm{y}_f)\in \{0,…,1\}^{H×W×3}$
3.1.2 Conditional Critic PatchGAN: 输入图像 $\mathrm{I}\dashrightarrow \mathrm{Y}_{\mathrm{I}}\in \mathbb{R}^{H/2^6×W/2^6}$
并且对判别器进行改进,加入额外的回归判别类别。
3.2 Learning the model 损失函数
3.2.1 Image Adversarial Loss 判断图片是生成的还是真实的。
和StarGAN的损失一样。
3.2.2 Attention Loss 这个损失是针对attention mask A 和 color mask C.
Total Variation Regularization
这个公式的初步感觉是A要尽可能平缓,并且A中的元素尽可能小。
根据作者的说法,是为了保证A不变成全是1的矩阵,并且为了保证更加平滑的空间结合。以代码为准。
3.2.3 Conditional Expression Loss 这个应该和starGAN的判断图片属性分类正确损失是一样的。
3.2.4 Identity Loss 这个应该就是starGAN的重构损失
这个损失是为了保证生成前后图片的id是一样的。
3.2.5 Full Loss 4. Implementation Details The attention mechanism guaranties a smooth transition between the morphed cropped face and the original image.
也就是说 attention mechanism 能够保证生成的图片很好地再贴回去。
4.1 Single Action Units Edition
[x] 这里的AU是什么? intensity怎么理解?
AU:https://www.cs.cmu.edu/~face/facs.htm
intensity: https://github.com/TadasBaltrusaitis/OpenFace/wiki/Action-Units
4.2 Simultaneous Edition of Multiple AUs
4.3 Discrete Emotions Editing
作者生成的图片比StarGAN更清晰。
4.4 High Expressions Variability 4.5 Images in the Wild
作者先检测到人脸,然后扣下来,做训练测试,然后再贴回去,与原图保持了一样的清晰度,个人猜测是因为表情的变化只在人脸的中央就可以完成,不涉及到背景的变换,如果涉及到背景的变换,那么是否还能保证贴回去与原图保持一致性。
4.6 Pushing the Limits of the Model
5. code 5.1 生成器Generator GANimation的Generator的主体网络和starGAN的Generator的主体网络一致,只是多加了一个conv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Generator (NetworkBase ): """Generator. Encoder-Decoder Architecture.""" def __init__ (self, conv_dim=64 , c_dim=5 , repeat_num=6 ): super (Generator, self).__init__() self._name = 'generator_wgan' layers = [] layers.append(nn.Conv2d(3 +c_dim, conv_dim, kernel_size=7 , stride=1 , padding=3 , bias=False )) layers.append(nn.InstanceNorm2d(conv_dim, affine=True )) layers.append(nn.ReLU(inplace=True )) curr_dim = conv_dim for i in range (2 ): layers.append(nn.Conv2d(curr_dim, curr_dim*2 , kernel_size=4 , stride=2 , padding=1 , bias=False )) layers.append(nn.InstanceNorm2d(curr_dim*2 , affine=True )) layers.append(nn.ReLU(inplace=True )) curr_dim = curr_dim * 2 for i in range (repeat_num): layers.append(ResidualBlock(dim_in=curr_dim, dim_out=curr_dim)) for i in range (2 ): layers.append(nn.ConvTranspose2d(curr_dim, curr_dim//2 , kernel_size=4 , stride=2 , padding=1 , bias=False )) layers.append(nn.InstanceNorm2d(curr_dim//2 , affine=True )) layers.append(nn.ReLU(inplace=True )) curr_dim = curr_dim // 2 self.main = nn.Sequential(*layers) layers = [] layers.append(nn.Conv2d(curr_dim, 3 , kernel_size=7 , stride=1 , padding=3 , bias=False )) layers.append(nn.Tanh()) self.img_reg = nn.Sequential(*layers) layers = [] layers.append(nn.Conv2d(curr_dim, 1 , kernel_size=7 , stride=1 , padding=3 , bias=False )) layers.append(nn.Sigmoid()) self.attetion_reg = nn.Sequential(*layers) def forward (self, x, c ): c = c.unsqueeze(2 ).unsqueeze(3 ) c = c.expand(c.size(0 ), c.size(1 ), x.size(2 ), x.size(3 )) x = torch.cat([x, c], dim=1 ) features = self.main(x) return self.img_reg(features), self.attetion_reg(features)
5.2 Discriminator Discriminator和StarGAN 的Discriminator完全一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Discriminator (NetworkBase ): """Discriminator. PatchGAN.""" def __init__ (self, image_size=128 , conv_dim=64 , c_dim=5 , repeat_num=6 ): super (Discriminator, self).__init__() self._name = 'discriminator_wgan' layers = [] layers.append(nn.Conv2d(3 , conv_dim, kernel_size=4 , stride=2 , padding=1 )) layers.append(nn.LeakyReLU(0.01 , inplace=True )) curr_dim = conv_dim for i in range (1 , repeat_num): layers.append(nn.Conv2d(curr_dim, curr_dim*2 , kernel_size=4 , stride=2 , padding=1 )) layers.append(nn.LeakyReLU(0.01 , inplace=True )) curr_dim = curr_dim * 2 k_size = int (image_size / np.power(2 , repeat_num)) self.main = nn.Sequential(*layers) self.conv1 = nn.Conv2d(curr_dim, 1 , kernel_size=3 , stride=1 , padding=1 , bias=False ) self.conv2 = nn.Conv2d(curr_dim, c_dim, kernel_size=k_size, bias=False ) def forward (self, x ): h = self.main(x) out_real = self.conv1(h) out_aux = self.conv2(h) return out_real.squeeze(), out_aux.squeeze()
5.3 train D 这里训练D的过程和starGAN有所不同,并且超参数也有所不同。
starGAN:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 loss_D, fake_imgs_masked = self._forward_D() self._optimizer_D.zero_grad() loss_D.backward() self._optimizer_D.step() loss_D_gp= self._gradinet_penalty_D(fake_imgs_masked) self._optimizer_D.zero_grad() loss_D_gp.backward() self._optimizer_D.step() def _forward_D (self ): fake_imgs, fake_img_mask = self._G.forward(self._real_img, self._desired_cond) fake_img_mask = self._do_if_necessary_saturate_mask(fake_img_mask, saturate=self._opt.do_saturate_mask) fake_imgs_masked = fake_img_mask * self._real_img + (1 - fake_img_mask) * fake_imgs d_real_img_prob, d_real_img_cond = self._D.forward(self._real_img) self._loss_d_real = self._compute_loss_D(d_real_img_prob, True ) * self._opt.lambda_D_prob self._loss_d_cond = self._criterion_D_cond(d_real_img_cond, self._real_cond) / self._B * self._opt.lambda_D_cond d_fake_desired_img_prob, _ = self._D.forward(fake_imgs_masked.detach()) self._loss_d_fake = self._compute_loss_D(d_fake_desired_img_prob, False ) * self._opt.lambda_D_prob return self._loss_d_real + self._loss_d_cond + self._loss_d_fake, fake_imgs_masked def _compute_loss_D (self, estim, is_real ): return -torch.mean(estim) if is_real else torch.mean(estim) def _gradinet_penalty_D (self, fake_imgs_masked ): alpha = torch.rand(self._B, 1 , 1 , 1 ).cuda().expand_as(self._real_img) interpolated = Variable(alpha * self._real_img.data + (1 - alpha) * fake_imgs_masked.data, requires_grad=True ) interpolated_prob, _ = self._D(interpolated) grad = torch.autograd.grad(outputs=interpolated_prob, inputs=interpolated, grad_outputs=torch.ones(interpolated_prob.size()).cuda(), retain_graph=True , create_graph=True , only_inputs=True )[0 ] grad = grad.view(grad.size(0 ), -1 ) grad_l2norm = torch.sqrt(torch.sum (grad ** 2 , dim=1 )) self._loss_d_gp = torch.mean((grad_l2norm - 1 ) ** 2 ) * self._opt.lambda_D_gp
5.4 train G 这一部分和starGAN的训练类似,比starGAN多一个mask的平滑loss。
starGAN:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def _forward_G (self, keep_data_for_visuals ): fake_imgs, fake_img_mask = self._G.forward(self._real_img, self._desired_cond) fake_img_mask = self._do_if_necessary_saturate_mask(fake_img_mask, saturate=self._opt.do_saturate_mask) fake_imgs_masked = fake_img_mask * self._real_img + (1 - fake_img_mask) * fake_imgs d_fake_desired_img_masked_prob, d_fake_desired_img_masked_cond = self._D.forward(fake_imgs_masked) self._loss_g_masked_fake = self._compute_loss_D(d_fake_desired_img_masked_prob, True ) * self._opt.lambda_D_prob self._loss_g_masked_cond = self._criterion_D_cond(d_fake_desired_img_masked_cond, self._desired_cond) / self._B * self._opt.lambda_D_cond rec_real_img_rgb, rec_real_img_mask = self._G.forward(fake_imgs_masked, self._real_cond) rec_real_img_mask = self._do_if_necessary_saturate_mask(rec_real_img_mask, saturate=self._opt.do_saturate_mask) rec_real_imgs = rec_real_img_mask * fake_imgs_masked + (1 - rec_real_img_mask) * rec_real_img_rgb self._loss_g_cyc = self._criterion_cycle(rec_real_imgs, self._real_img) * self._opt.lambda_cyc self._loss_g_mask_1 = torch.mean(fake_img_mask) * self._opt.lambda_mask self._loss_g_mask_2 = torch.mean(rec_real_img_mask) * self._opt.lambda_mask self._loss_g_mask_1_smooth = self._compute_loss_smooth(fake_img_mask) * self._opt.lambda_mask_smooth self._loss_g_mask_2_smooth = self._compute_loss_smooth(rec_real_img_mask) * self._opt.lambda_mask_smooth def _compute_loss_smooth (self, mat ): return torch.sum (torch.abs (mat[:, :, :, :-1 ] - mat[:, :, :, 1 :])) + \ torch.sum (torch.abs (mat[:, :, :-1 , :] - mat[:, :, 1 :, :]))
5.5 保存图片 这个保存图片在starGAN就没有太理解,在这里又看到了类似的,才理解这是对输入图片归一化的反向操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from torchvision.utils import save_imagedef denorm (self, x ): """Convert the range from [-1, 1] to [0, 1].""" out = (x + 1 ) / 2 return out.clamp_(0 , 1 ) save_image(self.denorm(x_concat.data.cpu()), sample_path, nrow=1 , padding=0 ) import numpy as npmean = [0.5 , 0.5 , 0.5 ] std = [0.5 , 0.5 , 0.5 ] for i, m, s in zip (img, mean, std): i.mul_(s).add_(m) image_numpy = img.numpy() image_numpy_t = np.transpose(image_numpy, (1 , 2 , 0 )) image_numpy_t = image_numpy_t*254.0 image_numpy_t.astype(np.uint8)
5.6 其他 没有实际跑这个代码,所以对于一些细节不是很清晰,尤其是数据处理那里,暂时根据查到的AU资料理解成17个AU(但1, 2, 4, 5, 6, 7, 9, 10, 12, 14, 15, 17, 20, 23, 25, 26, 28, and 45是18个AU),每个AU是一个0~5的数字。
但是对于作者所说的能够生成连续的表情变换,这一点只能在测试代码中看出,但是在训练的时候并没有特意去表示连续的变化,暂时对于连续的变化存疑。
主要是openface这个库有点晕,等数据集下载之后试试。
https://github.com/albertpumarola/GANimation/issues/45 https://github.com/albertpumarola/GANimation/issues/62 https://github.com/albertpumarola/GANimation/issues/43 https://github.com/albertpumarola/GANimation/issues/32 https://github.com/albertpumarola/GANimation/issues/25