CVPR2020-TVOS-semi-A Transductive Approach for Video Object Segmentation
code
微软的论文
半监督目标分割:Davis2017,Youtube-VOS
semi-supervised
考虑了时间(采样)和空间(相似矩阵)
Resnet-50
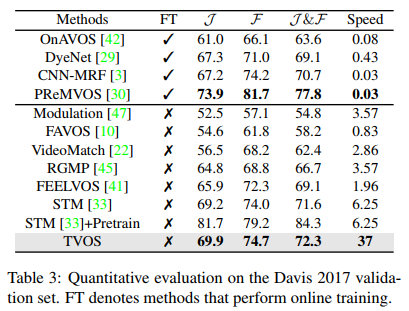
不需要其他数据集预训练
采用了resnet50作为backbone,并且修改了layer4的通道数,使输出从2048变为1024,1/8
在backbone的基础上添加1x1卷积,通道:1024—256
训练和测试时使用的时间采样和motion不一样。
训练:使用公式7和8,连续采样10张,256*256
loss:对应论文中的公式7和8,因为prediction = batch_global_predict(global_similarity, ref_label)得出的prediction本身已经满足和为1,不需要再次softmax
inference:sparse sample+motion prior(小于9张时取连续的9张,大于9张从t-1开始按照sparse取)
predict 对应论文中的公式6,先计算特征相似度,再乘以空间相似度
annotation_centroids.npy用于从rgb映射到class, 22*3,训练时annotation会缩小,所以标签可能会不是整数值
训练简单,测试快。
测试时只用到了模型提取特征值。
| 数据集 | J | F | J&F | speed | 备注 |
|---|---|---|---|---|---|
| Davis-2017-val | 69.9 | 74.7 | 72.3 | 37 | 不需要在其他数据集上预训练,测试时不需要fine-tune模型 |