1. RotationNet-paper
Asako Kanezaki, Yasuyuki Matsushita2, and Yoshifumi Nishida.
Asako Kanezaki 是日本东京研究所专门研究3D的一个老师。
code-pytorch: https://github.com/kanezaki/pytorch-rotationnet
code-caffe: https://github.com/kanezaki/rotationnet
project: https://kanezaki.github.io/rotationnet/
MIMO data: https://github.com/kanezaki/MIRO
作者是使用caffe版本提交的论文,我也只是看了看代码,作为理解作者论文的辅助,实际没有跑过代码。
这篇博客以代码和论文混杂,因为是借助代码理解论文的,又因为不主要做这个方向,所以并没有在意精度什么的。
1.1 出发点
作者不仅想要预测出图片的类别label,还想预测出图片的view-points.
我觉得作者的创新点在于对view的状态顺序编码成view-rotation,限定了view的取值空间,使预测的结果变成了哪种view-rotaion的view准确率高。
因为在一般情况下,想到的是直接预测view,而不是view-rotation.
1.2 网络架构
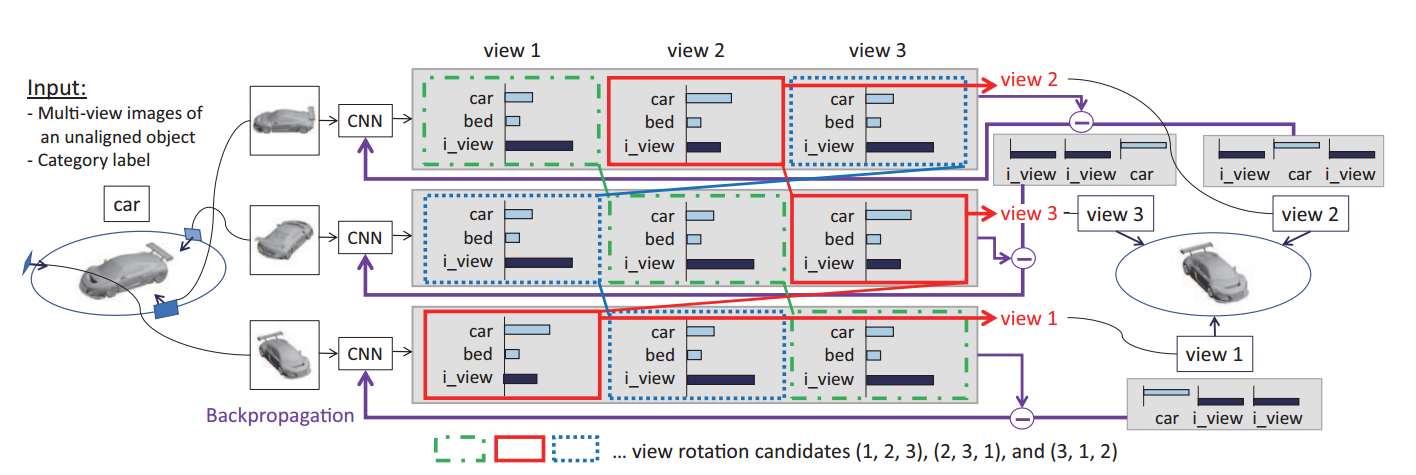
1.2.1 训练过程:
以MIRO数据集、case=3为例,nview=160,vcand=(16, 160),view-rotation=16,num-classes=12.
这里的view-roration,我的理解是view的排列方式,但是还是不太顺。
输入的图片个数batch-size必须是nview的倍数,以输入一个样本的160个角度的图片为例,即batch-size=160,nsamp=1,不影响后续的分析,因为每个样本没有任何关系。
输出是output=batch-size x ((num_classes+1) * nview)= 160 x (13 x 160). 可以理解成对每一个图片,输出网络架构的一行,可以理解成160张图片在160个view下属于13个类的概率。
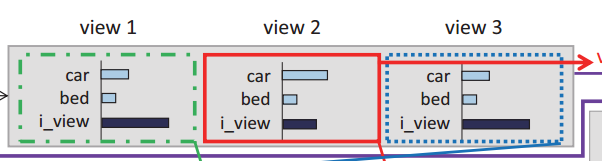
预测view rotation: 利用下面的预测view公式,求log并相减得到output- = (160x160) x 12 x 1,可以理解成一个矩阵: (160x160) x 12,每行表示当前图片当前view下的属于各类的概率,第一个160行表示第一张图片在160个view下的概率分布,第二个160行表示第二张图片在160个view下的概率分布。scores = (16 x 12 x 1)。scores可以理解成当前view-rotation下这160张图片一起属于各类的概率。
1 | output = model(input_var) |
生成动态真值target-:已知这160张图片的真值target[ n * nview ],假设是第3类,j-max表示第j-max个view-rotation下,预测为第3类的概率最大,继而生成动态真值target-=(target.size(0) x nview)=160 x 160=25600,可以理解成160张图片在160个view下的真值,在j-max个view-rotation对应的view设置为类别3,其余的设置为13.
1 | target_ = torch.LongTensor( target.size(0) * nview ) |
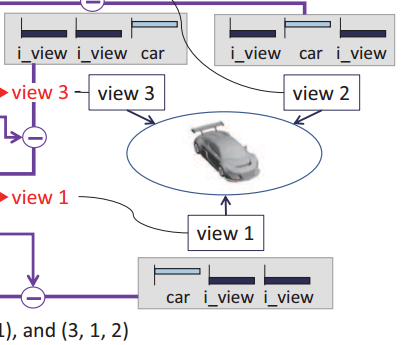
1.2.2 验证过程
与训练类似,可以得到output- = (160x160) x 12 x 1,可以理解成一个矩阵: (160x160) x 12,每行表示当前图片当前view下的属于各类的概率,第一个160行表示第一张图片在160个view下的概率分布,第二个160行表示第二张图片在160个view下的概率分布。scores = (16 x 12 x 1)。scores可以理解成每个view-rotation下这160张图片一起属于各类的概率。
j-max表示在第j-max个view-rotation下,scores可以找到最大概率。
output[n] 表示每连续的160张图片一起属于某类的概率。
1 | output = model(input_var) |
1.2.3 测试过程
因为caffe代码没有看懂,所以根据作者的论文和代码猜一下,当输入的图片没有160张,假设只有100张图片,那么又该怎么做?
模型的输出是output=batch-size x ((num_classes+1) * nview)= 100 x (13 x 160),那么怎么求scores?
求scores是需要全部view的信息的。这里不会了,尽管已经给出了公式,但是公式只能算出output-,没有score,不会了。
坐等作者回复。
Our method is available only when the relative poses of test images are known. For example, if you captured three images where the second image is 22.5 degrees forward from the first image and the third image is 45 degrees forward from the second image, then the images should be indexed as (0, 1, 3). Then you would get 3x160x12 output values. An easy way to proceed is to create a 160x160x12 “output2” which has zero values, and then insert the output values as “output2[0] = output[0]; output2[1] = output[1]; output2[3] = output[2];”. (In our paper, we used LSD-SLAM to calculate relative poses of test images.)
根据作者的回复,不难理解,给定的测试图片是需要预先知道测试图片序列的相对位置的。