Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
Gradient-weighted Class Activation Mapping
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam
code-torch: https://github.com/ramprs/grad-cam/
code-pytorch: https://github.com/jacobgil/pytorch-grad-cam
code-keras: https://github.com/jacobgil/keras-grad-cam
参考链接:
- https://www.jianshu.com/p/b2f7efe10ad8
- https://www.jianshu.com/p/1d7b5c4ecb93
- http://spytensor.com/index.php/archives/20/
- https://www.jianshu.com/p/e4fa1348e5bc
1. 声明
最近在看到一篇person-reid的文章Re-Identification with Consistent Attentive Siamese Networks,其中涉及到了Grad-CAM,所以简单学习一下Grad-CAM,但不作为重点。
2018-12-18
在使用的过程中,发现自己写的这篇博客不太容易让自己一目了然,所以根据链接来进行更新一次。
2018-12-20
在重新看论文person-reid的过程中,发现其中涉及到的网络架构师GAIN,所以补充GAIN的说明及其代码。此时,这篇的重点变成了Grad-CAM和GAIN。
2. 前言
对于深度模型的可解释性和可视化,现在已经研究出了一些方法,包括不限于Deconvolution, Guided-Backpropagation, CAM, Grad-CAM.
其中 Deconvolution 和 Guided-Backpropagation 得到更偏向于细粒度图, CAM 和 Grad-CAM 得到更偏向于类区分的热力图。
各种可视化方法及其效果图参见:https://github.com/utkuozbulak/pytorch-cnn-visualizations
参考链接: https://blog.csdn.net/geek_wh2016/article/details/81060315
2.1 Deconvolution
Deconvolution: Visualizing and Understanding Convolutional Networks
code: https://github.com/kvfrans/feature-visualization
综述: 这篇paper是CNN可视化的开山之作(由 Lecun 得意门生 Matthew Zeiler 发表于2013年),主要解决了两个问题:
- why CNN perform so well?
- how CNN might be improved?
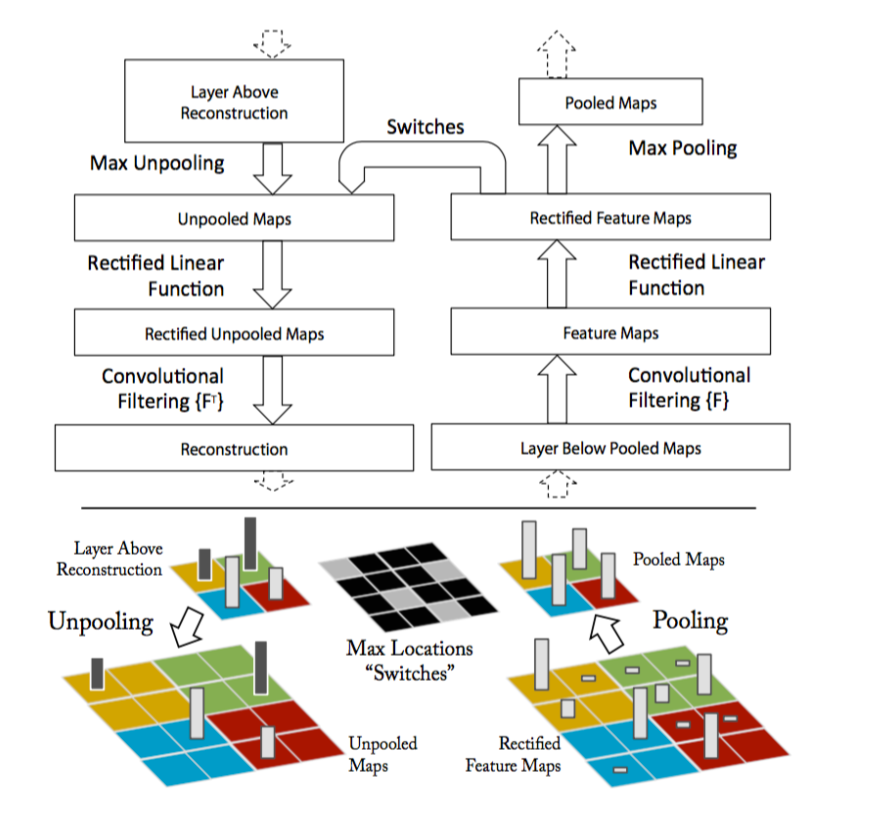
实现: 对于CNN,可视化就是整个过程的逆过程,即Unpooling+ReLU+Deconv.
- Unpooling: 记录max-pool的位置,即Switches表格,unpooling时,最大值放回该位置,其他位置放0.
- ReLU: 继续使用ReLU.
- Deconv: 使用相同卷积核的转置作为新的卷积核,对特征进行卷积.
参考链接:
- http://kvfrans.com/visualizing-features-from-a-convolutional-neural-network/
- https://blog.csdn.net/Julialove102123/article/details/78292807
- https://blog.csdn.net/gm_margin/article/details/79335140
2.2 Guided-Backpropagation
Guided-Backpropagation: Striving for Simplicity: The All Convolutional Net
反向传播、反卷积和导向反向传播都是反向传播,区别在于经过 ReLU 层时对梯度的不同处理策略。在这篇论文中有详细的解释。
计算公式如下:
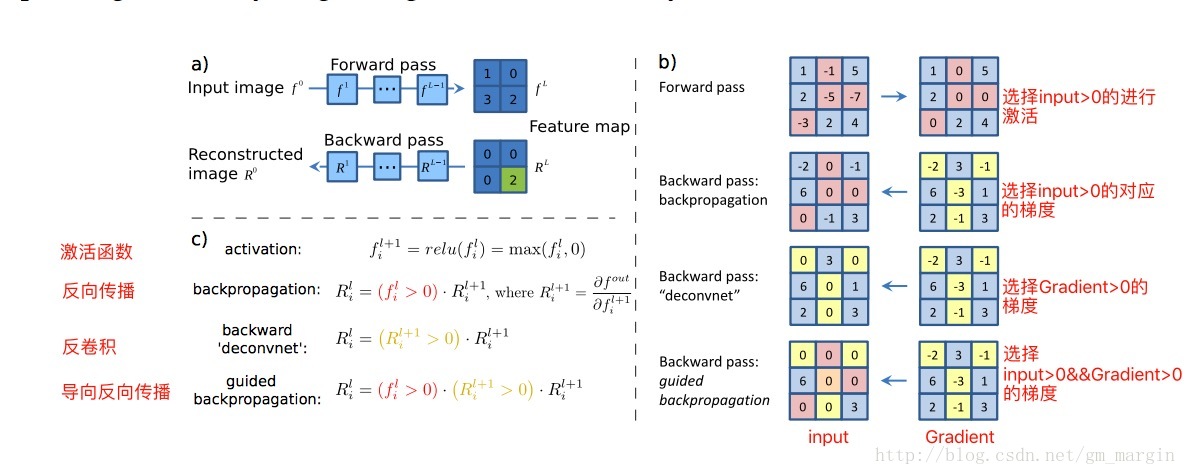
文中提出使用 stride convolution 代替 pooling,研究这种结构的有效性。
效果显示如下:

可以看出 Guided-Backpropagation 主要提取对分类有效果的特征,但是与是哪类没有关系。
2.3 CAM
CAM: Learning Deep Features for Discriminative Localization
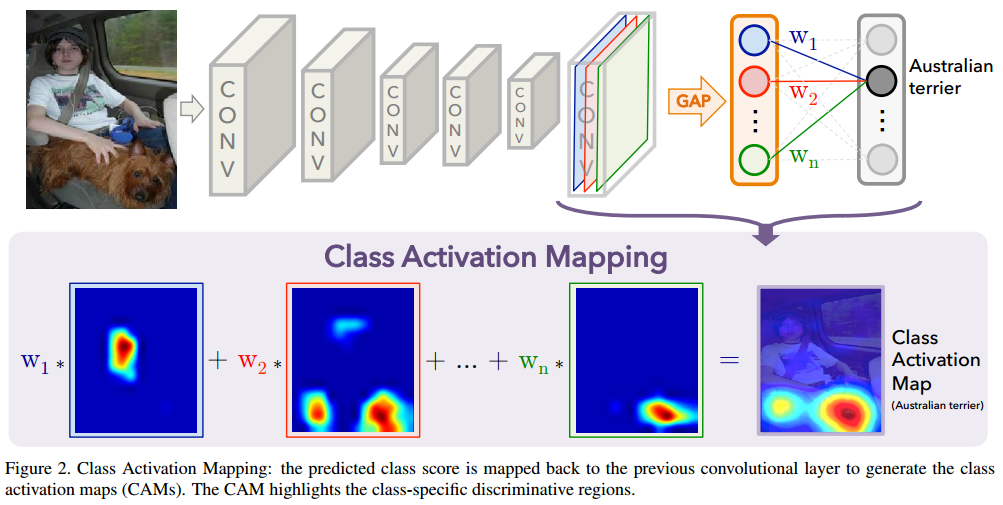
综述:论文重新审视了global average pooling (GAP) 的有效性,并详细阐述了GAP如何使得CNN有优异的目标定位能力。
介绍:摒弃FC,使用GAP。
实现:
2.4 Grad-CAM
Grad-CAM 是CAM的改进版, 与 CAM 的不同点在于前者的特征加权系数是反向传播得到的,后者的特征加权系数是分类器的权重。
Grad-CAM 可以加载到任意网络架构上,而不需要修改网络架构,而CAM必须使用GAP。
下面会详细介绍。
2.5 GAIN
GAIN: Tell Me Where to Look: Guided Attention Inference Network
code: https://github.com/alokwhitewolf/Guided-Attention-Inference-Network
GAIN 是 Grad-CAM 的改进版,Grad-CAM只能可视化解释现有的网络结构的结果,却不能指导网络架构,GAIN可以指导网络修正错误,关注更正确的位置。
问题:在船识别的过程中,网络的关注点是水面而不是船。
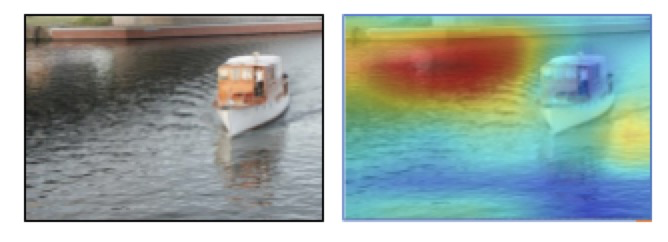
实现:通过最小化遮挡图像的物体来训练。
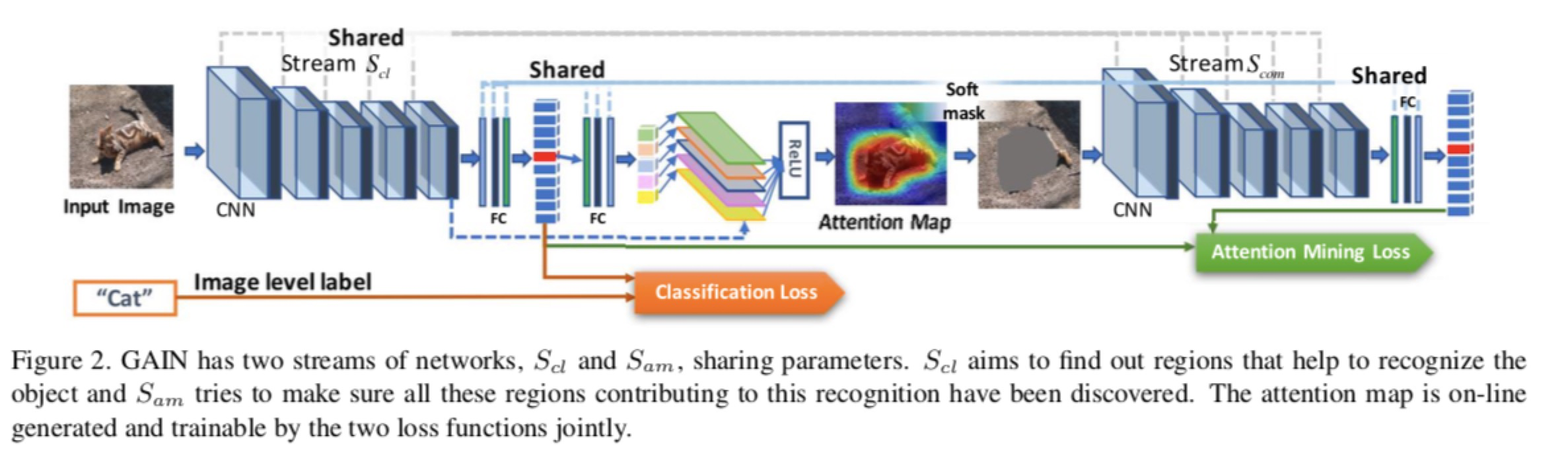
整体网络架构中,只有一个网络,两个处理流都是共享同一个网络。
公式:损失函数
扩展:如果有额外的监督真值,比如分割,那么可以进行扩充网络
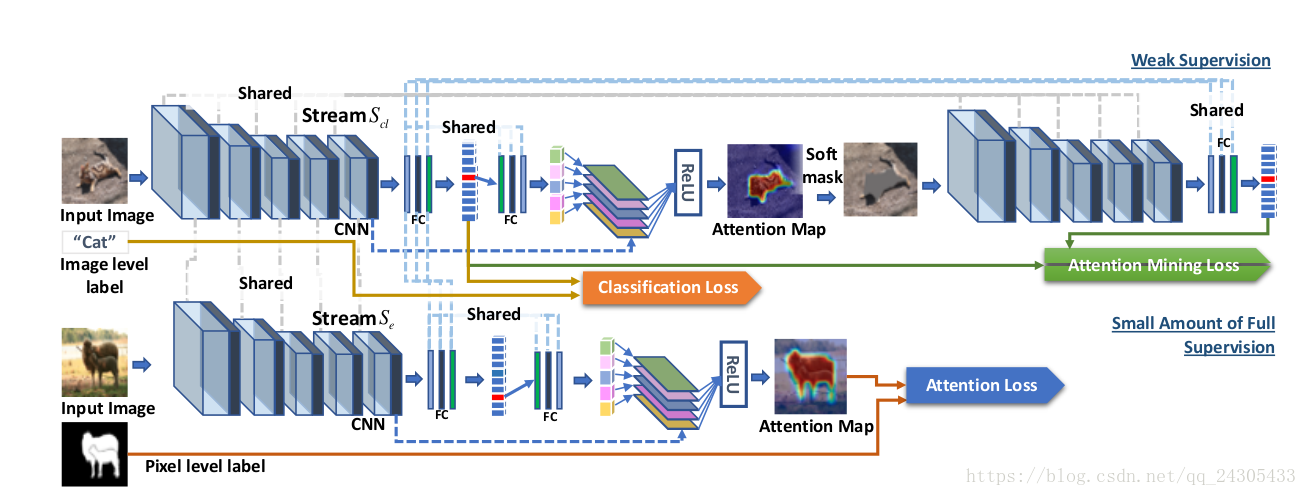
2.5.1 GAIN-code
第一步:训练分类网络
FCN:
1 | self.conv1_1 = L.Convolution2D(3, 64, 3, 1, 1) |
FCN-v1.0: 普通的分类
1 | self.conv1_1 = L.Convolution2D(3, 64, 3, 1, 1) |
loss:
1 | # cl_output=classify(image) |
第二步:训练GAIN
1 | self.GAIN_functions = collections.OrderedDict([ |
通过分类结果获取mask:
1 | def stream_cl(self, inp, label=None): |
$L_{cl}$
1 | gcam, cl_scores, class_id = self._optimizers['main'].target.stream_cl(image, gt_labels) |
$L_{am}$
1 | masked_output = self._optimizers['main'].target.stream_am(masked_image) |
备注: $L{cl}$和$L{am}$完全共享网络。
3. Introduction
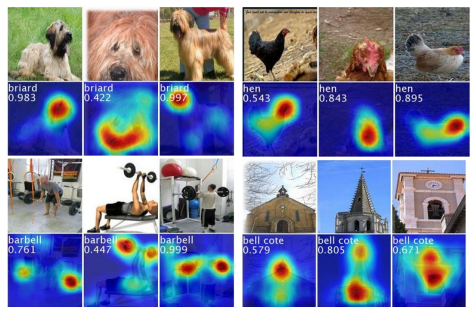
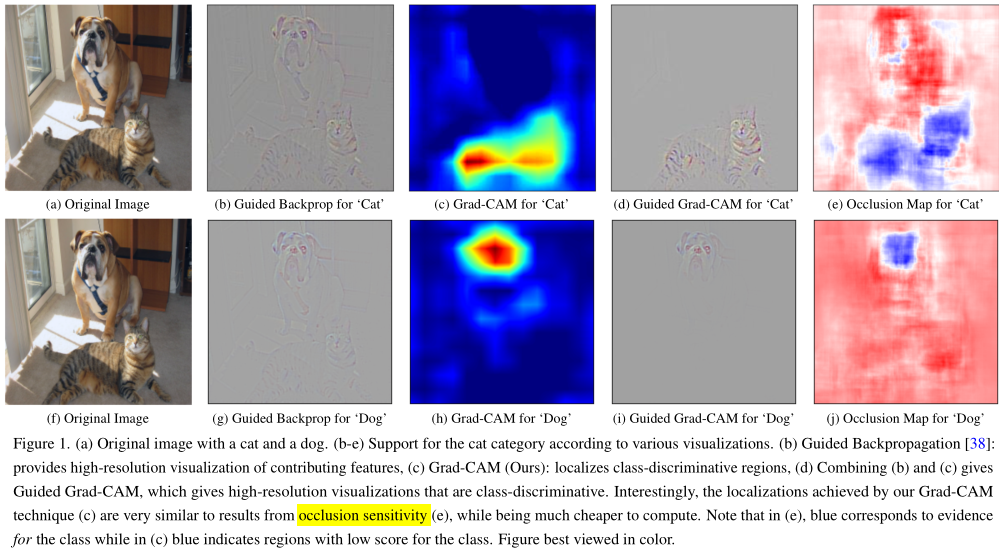
可视化即应该满足高分辨率,也应该满足类别定位能力。
示例图像
4. Approach
CAM
在CAM中,一个全连接层替换成GAP,参见上面的CAM图,则分类任务可以表示成
其中,$y^c$表示分类结果,$wk^c$表示第k个特征图(kxhxw)对第c个类别的贡献,即全连接层的系数,$Z$表示特征图的大小,$Z=h\cdot w$,$A{ij}^k$表示第k个特征图。
则 CAM 的输出图表示为:
Grad-CAM
在Grad-CAM中,权重系数是通过反向传播得到的。
则Grad-CAM的输出图表示为:
可以证明,Grad-CAM与CAM的公式是同一个公式的变形。
Guided Grad-CAM
Guided Grad-CAM 是将 Grad-CAM 与 Guided Backpropagation 得到的输出图简单地点乘,从而获得类区分定位的高分辨率细节图。
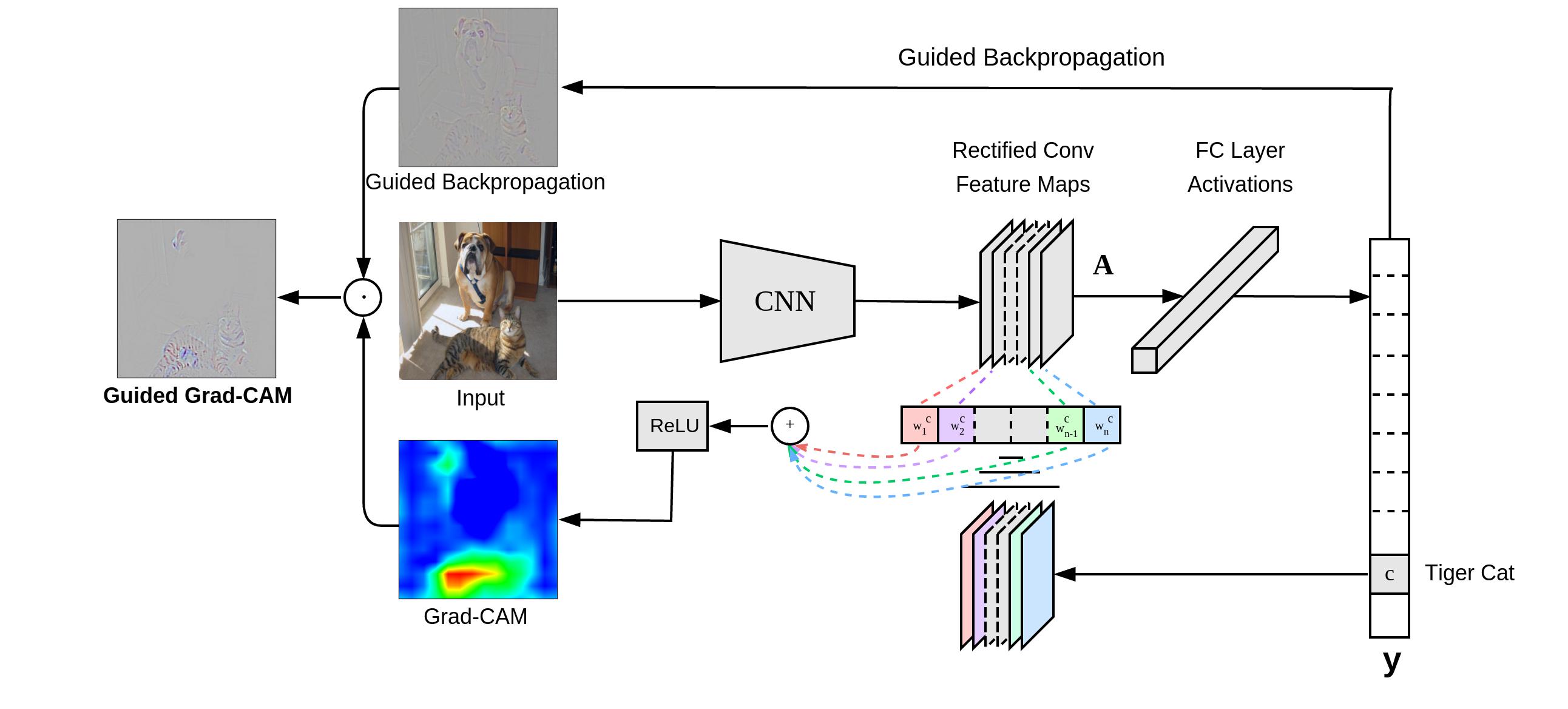
同时作者还分析了CNN分类错误的样本。
5. 代码
对于pytorch代码进行分析
5.1 Grad-CAM
计算Grad-CAM:
反向传播:先计算出当前图片的分类结果output(size:1*5)(假设共5类),选出最优分类结果,假设是第2类,然后令one-hot=[0,1,0,0,0],求得sum-one-hot=
cam: (H,W), ~(0,1)
1 |
|
显示Grad-CAM
1 |
|
5.2 GuidedBackpropReLUModel
gb: (C,H,W) 任意值
1 | class GuidedBackpropReLU(Function): |
5.3 Guided Grad-CAM
1 | cam_mask = np.zeros(gb.shape) |
6. 效果显示
原图

Grad-CAM

Guided-Backpropagation

Guided Grad-CAM
