CASN: Re-Identification with Consistent Attentive Siamese Networks
Meng Zheng, Srikrishna Karanam, Ziyan Wu, and Richard J. Radke
1. Introduction
这篇论文;
- 采用了Grad-CAM作为attention机制
- attention consistency: 采用Siamese-Net来使同一个人的attention位置是一样的
2. The Consistent Attentive Siamese Network
整体网络架构如图所示:
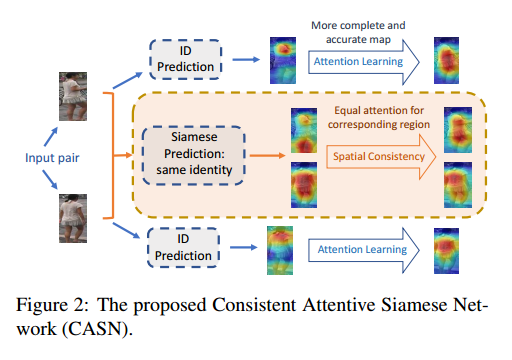
- 整体网络架构以IDE为基准网络,分为两部分:
- Identification Module
- Siamese Module
- Identification 和 Siamese 的特征提取网络共享,不同的只是fc层
2.1 The Identification Module
通过Grad-CAM的学习,已经知道了Grad-CAM的作用。
Identification loss:
Identification loss 更偏向于不同行人之间的判别信息。
Identification attention loss:
其中,给定一张图片$In$和类别$c_n$,Grad-CAM得到attention map $M_n$,做归一化操作,令$\Sigma(M_n)=sigmoid(\alpha(M_n-\beta))$,从而得到去掉attention区域的新图片$\overline{I_n}=I_n*(1-\Sigma(M_n))$,$\overline{y{c_n}}$是$\overline{I_n}$的预测值。
Identification attention loss 更偏向于行人的全部信息。
我的理解是$\overline{I_n}$中尽可能包含少的ID信息,所以预测出是$c_n$的概率更小,得到的attention区域尽可能地包括全部信息。
两种loss的效果对比图
2.2 The Siamese Module
Siamese Module 结构图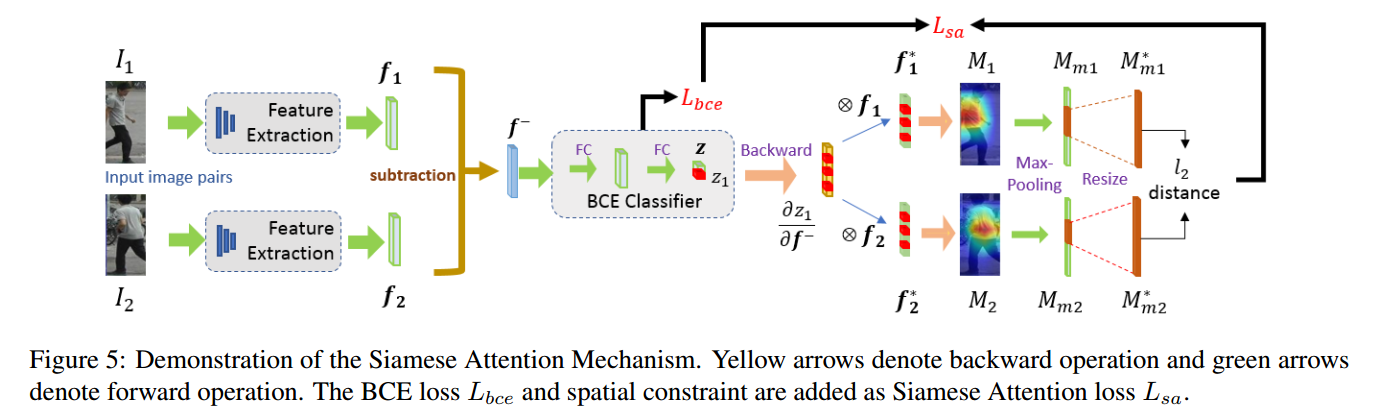
Siamese loss
Siamese attention loss
其中,$M{m1}$是$M_1$中超过阈值t的元素,$M{m1}^{resize}$是$M_{m1}$resize成相同大小的元素,主要是为了解决对齐问题。
通过与作者的沟通,作者认为$s_1$表示了$f_1$中对 BCE prediction 有用的信息。但是我没有见过这么表示对预测有用的信息的方法,之前只见过通过类别进行反向传播的(Grad-CAM),但是作者这么坚持,说明应该是有效的。
- Sorry I didn’t get your first question. By finding neurons in fi which are larger than zero, we find features in fi which have positive influence on BCE prediction.
- s1 is not I1’s class. We here call s1 the importance score, which collect scores for every neuron which contributes to BCE prediction.
2.3 Overall Design of the CASN
CASN的整体架构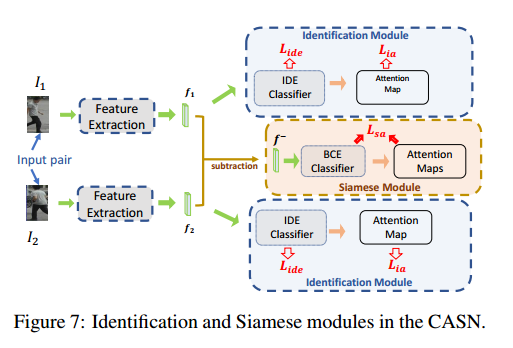
The overall loss
3. Experiments and Results
Implementation Details
- input: 288x144
- SGD: momentum=0.9
- lr=0.03
- epoch=40
- lr decay=0.1 after 30
- baseline: IDE and PCB( input: 384x128)
- batch=16
- test: we send the query and gallery as pair inputs to obtain attention maps $\parallel M{m1}^{resize}-M{m2}^{resize} \parallel _2$
Results
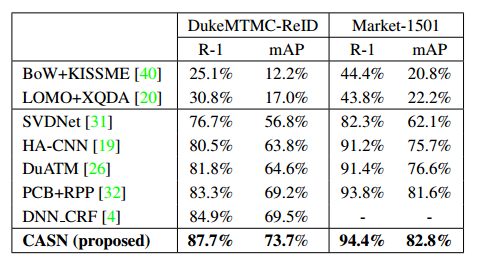
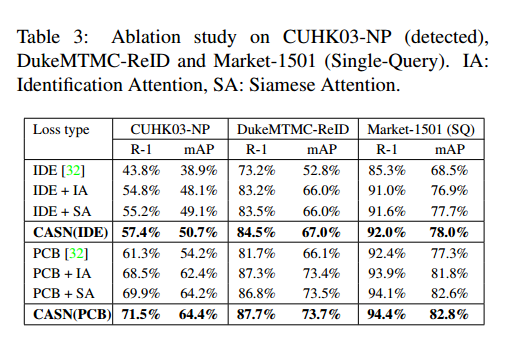
通过 Ablation Study , 对比CASN(IDE)、PCB,可以看出IA或者SA的作用和简单地分成6块达到的效果是类似的,这是不是说明了这种attention机制没有很大的作用,或者说分成6块就已经是一种很好的attention机制。
另外,+IA、+SA、CASN的对比,感觉IA或者SA一种机制就已经足够了,两者达到的效果是一样的,只使用一种就可以了。
4. Others
这篇论文不懂的地方:
- $L_{ia}$为什么可以直接这么写,不需要经过softmax之类的,或者不应该是每类的概率差不多么,
- $L_{ia}$还是经过相同的网络得到的吗?反向求导要怎么写?
- 根据Grad-CAM的以类别反向求导,方程5给我的感觉更像是$f$的特征和作为输入图片的分类预测值,合理性站不住脚。
- 在测试时,需要每次输入一对图片,是不是太慢了。
- 如果实验结果可以复现的话,那么IA我觉得还是很有用的,解释性也强。
参考: