0. 前言
因为在person-reid论文HHL中涉及到了starGAN,所以做一个StarGAN的阅读记录,并比较与CycleGAN的区别。
StarGAN Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo
code-pytorch-official: https://github.com/yunjey/stargan
code-tensorflow: <https://github.com/taki0112/StarGAN-Tensorflow >
1. Introduction
解决多域之间图像转换一对多的问题,本文主要针对人脸进行改变。
关键词:multi-domain image-image translation
效果:转换效果如图所示

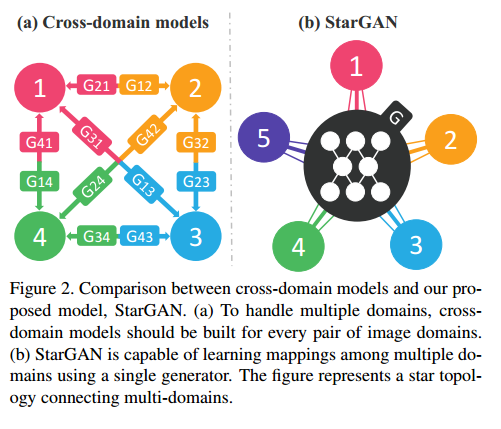
网络模型:CycleGAN和StarGAN模型对比
starGAN有一个生成器G,两个判别器。
备注:
multi-domain:单数据集的不同属性作为了一个domain
multi-datasets:不同数据集的不同属性
starGAN 分为multi-domain和multi-dataset两种。
2. Star Generative Adversarial Networks
2.1 Multi-Domain Image-to-Image Translation
starGAN: starGAN的训练模型
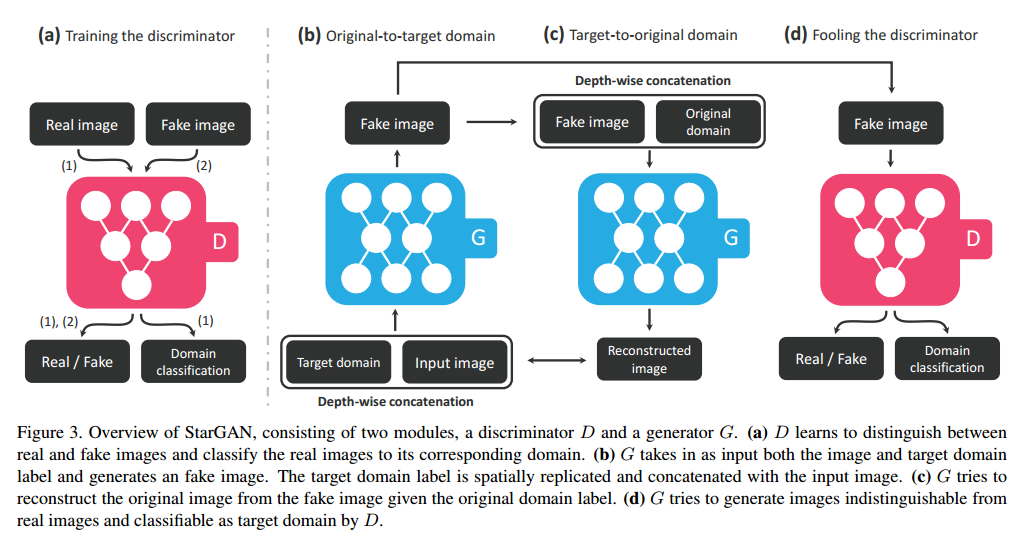
To achieve this, we train G to translate an input image x into an output image y conditioned on the target domain label c, G(x; c) -> y. We randomly generate the target domain label c so that G learns to flexibly translate the input image. We also introduce an auxiliary classifier [22] that allows a single discriminator to control multiple domains. That is, our discriminator produces probability distributions over both sources and domain labels, D:x->{$D{src}$(x); $D{cls}$(x)}
符号说明:符号表
| 符号 | 含义 |
|---|---|
| x | input image |
| c | target domain label |
| c’ | source domain label |
| y | generate image |
Loss: training loss
Adversarial Loss:(CycleGAN也有)对抗损失
Domain Classification Loss:(特有)分类损失
That is, we decompose the objective into two terms: a domain classification loss of real images used to optimize D, and a domain classification loss of fake images used to optimize G.
优化 D:
By minimizing this objective, D learns to classify a real image x to its corresponding original domain c’.
优化 G:
G tries to minimize this objective to generate images that can be classified as the target domain c.
Reconstruction Loss: (共有)重构损失
Full Objective: 共有
2.2. Training with Multiple Datasets

StarGAN也适用于多数据集间的转换,上述过程中的重构损失要求数据集之间的标签一致(???)。针对这个问题,作者引入Mask Vector.
Mask Vector: 修改真值。
$c_i$ represents a vector for the labels of the i-th dataset. The vector of the known label $c_i$ can be represented as either a binary vector for binary attributes or a one-hot vector for categorical attributes. For the remaining n−1 unknown labels we simply assign zero values.
这样的话,所有的c都需要变成$\tilde{c}$
3. Implementation
Improved GAN training: 为了稳定训练过程,替代方程1.
Network Architecture: 类似CycleGAN。
G: Leaky ReLU: 0.01
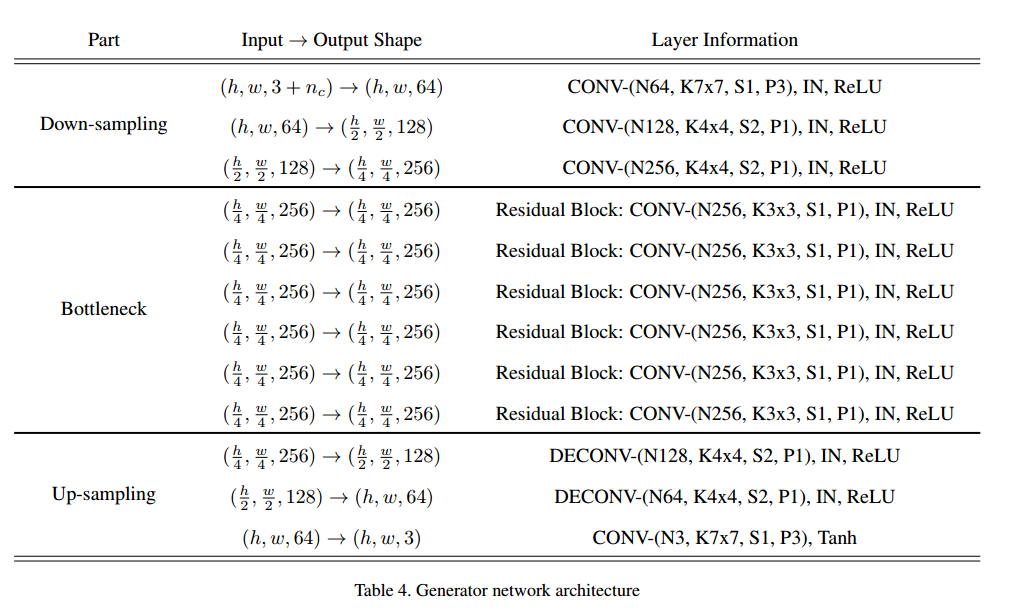
D: PatchGAN
现在网络架构可以看到的是作者使用的不是70x70的patchGAN,通过patchGAN的论文,也没有看到这种结构。

4. Experiments
4.1 Baseline Models

通过结果可以看出,在Gender这个属性,ICGAN的转换效果要更好一些,但是损失了ID信息。
4.2 Training
- Adam: $\beta_1=0.5, \beta_2=0.999$
- Updates: one generator update after five discriminator updates
- lr: For CelebA, 0.0001 for the first 100000 epochs, and linearly decay the lr to 0 over the next 100000 epochs. For the RaFD, 0.0001 for the first 100000 epochs, and linearly decay the lr to 0 over the next 100000 epochs.作者在论文写的是10和100,但是代码显示的是100000
- batch: 16
- input: For CelebA, crop: 178, resize: 128; For RaFD,
4.3 Results
作者通过人脸的转换实验,不仅说明了StarGAN在单数据集的不同domian中效果好,而且在多数据集的不同domian中效果也好。
5. 代码
在这里分析pytorch的代码,并对其中关键的代码进行解读。
如果不说明,则假设讨论单数据集的多域。
5.1 Model: G and D
Generator:
生成器Generator,结构与前面提到的网络架构一致,这里需要注意两点:
- 当训练集是单数据集的多domain时,label需要扩充成图片大小,一起输入网络(这里有个疑问:网络真得能知道后面的通道是label吗)
- 当训练集是多数据集的多domain时,label的维度是c+c2+2,因为有mask,同样需要广播成图片大小,一起输入网络
Discriminator:
判别器Discriminator,有个疑问是关于是感受野和计算损失的。
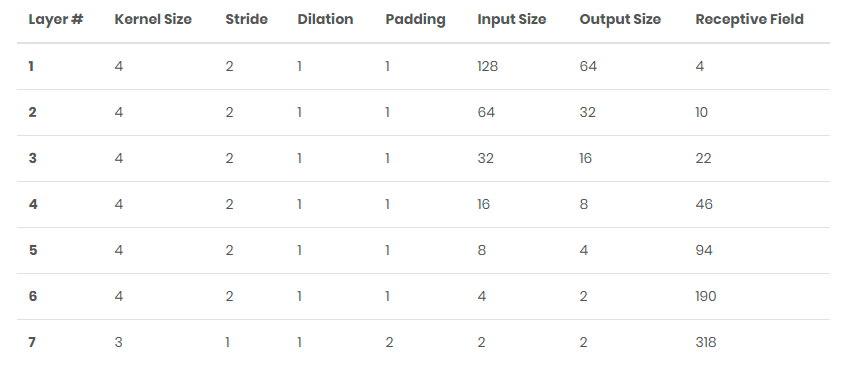
下面会提及到计算损失的。
1 | class ResidualBlock(nn.Module): |
5.2 input
对于任一张图片,其target label是随机取其他图片的label,而没有刻意去指定
1 | # label_org和label_trg可以认为是单个图片的真实label,形式可以是[0,1,1,0]或者4,根据不同的数据集形式进行处理,前者是多分类label,后者是单分类label,用于计算损失 |
5.3 train G and D
5.3.1 train D
这里需要对上述提到的损失函数做进一步处理。
判断图片真假损失:由方程6得:
判断原图片属性正确:由方程2得:
总损失:
备注:
- 在计算真假损失的时候,是直接求输出的均值,这一点不是很理解。
- 方程7的第三项的计算见gradient_penalty,对整个图片的梯度求和。
- 方程8的的求解见classification_loss,就是一个简单的分类损失。
- 不理解方程2为什么要加个符号?方程7也是符号正好相反?
1 | # =================================================================================== # |
1 | def gradient_penalty(self, y, x): |
1 | def classification_loss(self, logit, target, dataset='CelebA'): |
5.3.2 train G
与以往训练几个G之后才训练D不同,这里是训练几个D之后才训练G。
同样对上述提到的损失做进一步处理。
生成图片为真:由方程6得,与方程7正好相反:
生成图片的属性正确:由方程3得:
Reconstruction Loss: 重构损失
总损失
1 | # =================================================================================== # |
5.4 val
CelebA数据集:这里制作target domain label的方法分为头发属性(互相排斥)和其他属性(不排斥):对于选中的头发属性’Black_Hair’, ‘Blond_Hair’, ‘Brown_Hair’,则把5张图片的’Black_Hair’全部设为1,’Blond_Hair’, ‘Brown_Hair’设为0,作为第一个target domain label, 再把5张图片的’Blond_Hair’全部设为1,’Black_Hair’, ‘Brown_Hair’设为0,作为第二个target domain label, 再把5张图片的’Brown_Hair’全部设为1,’Black_Hair’,’Blond_Hair’ 设为0,作为第三个target domain label,对于其他属性,则直接取相反数做为第三个target domain label和第四个target domain label.
RaFD数据集:属于排斥属性,也和头发类似,对某一列全部设为1,其余设为0.
1 | c_org |
1 | def create_labels(self, c_org, c_dim=5, dataset='CelebA', selected_attrs=None): |
5.5 多数据集
在多数据集的情况下,损失函数大体不变,略微不同。
5.5.1 input
多数据集顺序输入
1 | for dataset in ['CelebA', 'RaFD']: |
1 | celeba_iter = iter(self.celeba_loader) |
5.5.2 train D and G
1 | # =================================================================================== # |
5.5.3 val and test
对当前图片生成两个数据集下不同属性的图片,也就是说,具有跨数据集生成图片的能力。
val:
1 | if (i+1) % self.sample_step == 0: |
test:
1 | for i, (x_real, c_org) in enumerate(self.celeba_loader): |
6. 其他
通过代码,我们可以猜出,对于starGAN,每一个domain都是一个二值属性,这些属性可以是互相排斥的,例如头发颜色,可以是不互相排斥的,并且这里和CycleGAN还是有一些区别的,CycleGAN的domain是数据集,source domain 和 target domain是风马牛不相及的,source domain和target domain有自己的风格,例如map数据集,是没有真值的,有的只是深度网络提取出的特征和70*70patchGAN.但是starGAN中,生成的图片和原始图片是一个数据集的,并且这两张图片不是要求风格一样,感觉这能应用到person-reid中也是神奇.
在图片真假的分类损失中,之前的GAN都是使用True和False来表示,这次换了一个新公式直接mean,还有点难理解。